
Operationalizing AI: From Proof-of-Concept
to Production
Building a proof of concept is the easy part. However, getting AI into production reliably, repeatably, and with the governance to sustain it is where most programs stall. Here is our perspective
on the structural reasons AI POCs fail to scale and a practical operationalization framework for CDOs and CDAOs navigating that transition.
There is a moment familiar to most CDOs and CDAOs. The proof of concept has been running for several weeks. The model performs well against the evaluation dataset. The stakeholders who attended the demonstration are encouraged. The slide deck shows strong projected returns. And then, in the months that follow, nothing moves to production.
The technical team cites data pipeline issues. The business unit has revised its priorities. Legal and compliance need more time to complete risk assessments. The infrastructure team raises concerns about integration. Eighteen months after the initial investment, the POC is still a POC, or has been quietly shelved.
This is not a rare scenario. It is the dominant outcome in enterprise AI programs today. According to Gartner, only 48 percent of AI projects make it into production, and the average journey from prototype to production takes eight months for the minority that do. At least 30 percent of generative AI projects will be abandoned after proof of concept by the end of 2025, due to poor data quality, inadequate risk controls, escalating costs, or unclear business value.
S&P Global Market Intelligence’s 2025 survey of over a thousand mid-level and senior professionals across North America and Europe found that organizations scrapped an average of 46 percent of AI proofs of concept before reaching broad adoption. That is a structural technology failure. And it repeats itself, at high cost, because most organizations have not built the conditions that production AI requires.
This article addresses two questions. First, why do well-performing POCs consistently fail to cross into production? Second, what does a CDO or CDAO need to put in place to close that gap reliably?
The Structural Gap Between POC and Production
The default explanation for a stalled AI program is usually technical: the model was not accurate enough, the infrastructure was not ready, the integration was too complex. These explanations are rarely wrong, but they are rarely the root cause either. They are symptoms of a deeper structural failure that predates the build.
BCG’s research with a thousand C-level executives found that only 26 percent of companies generate tangible value from AI, while 74 percent struggle to achieve meaningful scale. Their analysis points to a consistent pattern of resource allocation among successful programs: ten percent on algorithms, twenty percent on technology and data, and seventy percent on people and processes. Most organizations invert that ratio. They spend most of their effort on the model itself and treat the organizational and data infrastructure as a secondary concern.
The result is a POC that works in a controlled environment, against a curated dataset, with a team that has been managing it carefully, but cannot survive the conditions of a real production environment where data arrives in varied formats, edge cases are common, and no one person is monitoring the output continuously.
Informatica’s CDO Insights 2025 survey identifies the top obstacles to AI success as data quality and readiness, cited by 43 percent of respondents, followed by lack of technical maturity at 43 percent and shortage of skills at 35 percent. These obstacles do not emerge during the POC. They emerge during productionization, when the model is asked to operate on data it was not trained on, in conditions it was not built for, with accountability standards that no one defined during the build phase.
The following sections diagnose the four most consistent failure patterns and then provide the operationalization framework for each.
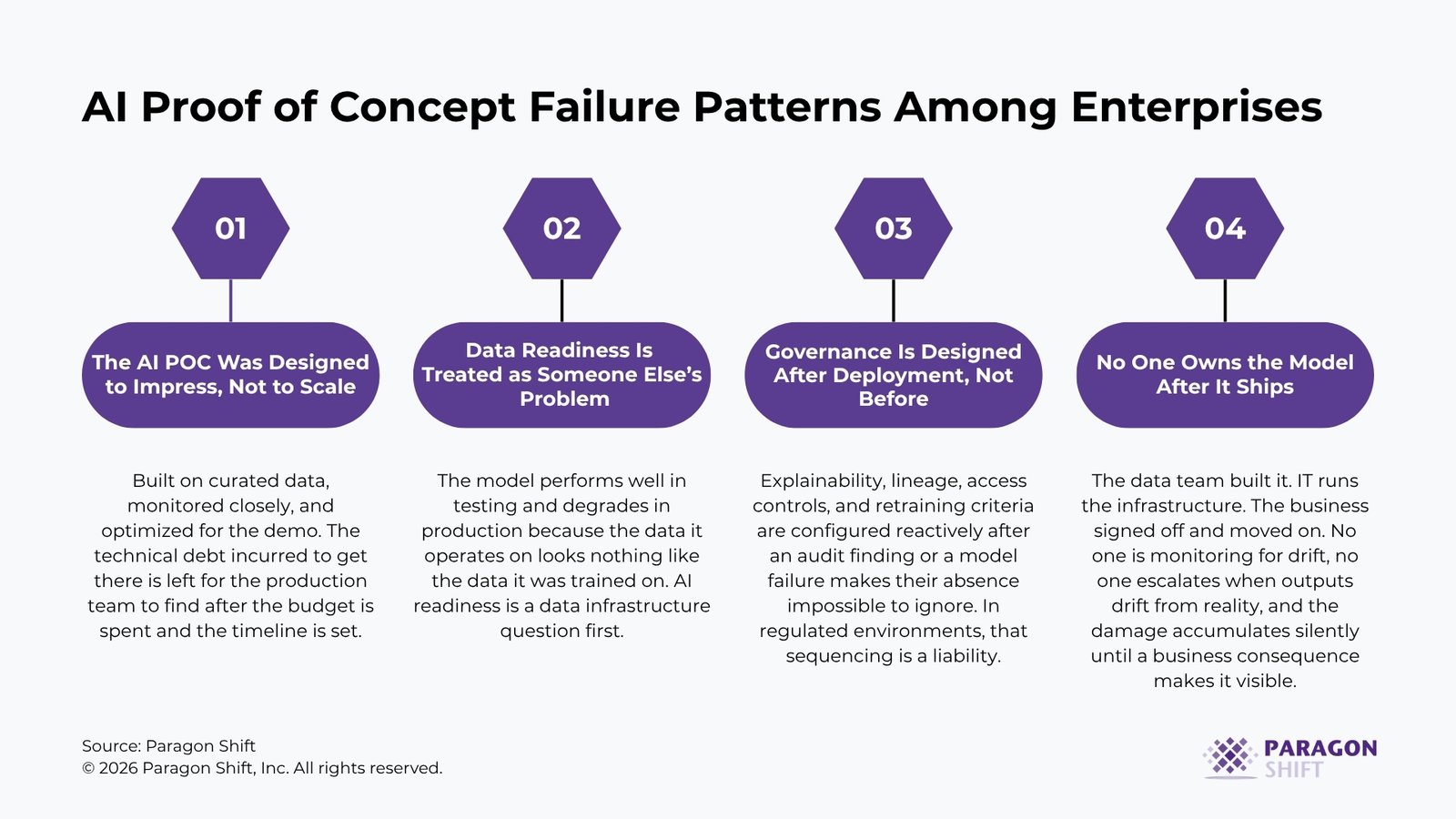
Failure Pattern 1: The AI POC Was Designed to Impress, Not to Scale
A proof of concept has a specific and limited purpose: to demonstrate that an AI approach is viable for a given problem. The danger is that organizations treat demonstration of viability as evidence of production readiness, which it is not.
POC environments are typically built on clean, manually curated data. They run in an isolated infrastructure. They are monitored closely by the data science team throughout. Exception handling is minimal because the team selects inputs that fit the model’s design. The result is a system that performs well under ideal conditions and has never been tested against the conditions it will face in production.
The failure is a design choice, not a technical accident. When the POC’s goal is to secure budget approval, the incentive is to show the best possible result in the shortest possible time. The technical debt incurred in reaching that result is left for the productionization team to discover, typically after the budget has already been allocated and a delivery timeline has been communicated to leadership.
The fix is a more rigorous POC design standard. Before a POC begins, the following questions should have documented answers: What does production data look like, including its quality issues? What are the failure modes if the model outputs incorrect results? Who is accountable for the output in production? What monitoring and retraining mechanism is planned from day one? A POC that cannot answer these questions is not production-ready evidence. It is a demonstration.
Failure Pattern 2: Data Readiness Is Treated as Someone Else’s Problem
Every AI model is a function of the data it was trained on and the data it will operate on in production. When the two data environments differ materially, model performance degrades. This is the condition known as data drift, and it is the most common cause of AI models that perform well in testing and poorly in the real world.
Data readiness for production AI is substantially more demanding than data readiness for a POC. In production, data pipelines must be reliable, governed, and monitored continuously. Schemas must be consistent. Missing values and outliers must be handled systematically, not manually. Business logic embedded in the data must be documented and stable. A 2024 McKinsey study found that 42 percent of enterprises deploying generative AI cited content integrity and data governance as one of their top three operational risks.
For CDOs and CDAOs, the practical implication is that AI readiness is, first and foremost, a question of data infrastructure. An organization whose source data is fragmented across systems with no consistent field definitions, no lineage tracking, and no quality monitoring is not in a position to reliably productionize AI, regardless of how capable the model is. The model will faithfully reflect the quality of the data it receives. When that data is inconsistent, the model’s outputs will be inconsistent as well.
This is why the data foundation work discussed in Paragon Shift’s earlier articles on data modernization and semantic layer governance is not a prerequisite for BI alone. It is the prerequisite for everything that sits above it, including production AI. Organizations that invest in that foundation before their AI programs begin will productionize at substantially higher rates than those that treat data preparation as a parallel workstream to model development.
Failure Pattern 3: Governance Is Designed After Deployment, Not Before
Most AI governance conversations in enterprise organizations happen reactively: after a model has been deployed, after an output has created a problem, or after a regulatory inquiry has made the absence of documented controls visible. That sequencing is expensive and avoidable.
Production AI carries governance requirements that have no equivalent in a POC environment. The model’s decision logic must be explainable to stakeholders and, in regulated industries, to auditors and regulators. Access to training data must be controlled and documented. Model outputs must be logged with enough fidelity to reconstruct how a specific decision was reached. Retraining schedules must be defined and approved. Sunset criteria must exist so that a model is retired when its performance no longer meets the standard required.
Gartner projects that by 2026, 60 percent of large enterprises will have deployed data lineage tools to address regulatory and operational risk, up from just 20 percent in 2023. That trajectory reflects a governance gap that regulators and boards are increasingly unwilling to accept as a temporary condition.
For a CDAO, the governance framework is not a compliance exercise. It is the mechanism that makes production AI trustworthy enough for business units to use, for auditors to review, and for leadership to stand behind. An AI model that produces correct outputs but cannot explain them is not a production-ready asset in any regulated environment. It is a liability.
The global MLOps market was valued at 1.7 billion dollars in 2024 and is projected to grow at a 37.4 percent compound annual growth rate through 2034. This growth reflects a fundamental shift in how enterprise AI programs are structured: building models is no longer the bottleneck. Deploying, governing, and maintaining them at scale is.
Failure Pattern 4: No One Owns the Model After It Ships
This is the failure pattern that receives the least attention in technical discussions and the most attention in post-mortems.
Production AI models are not static artifacts. They degrade over time as the data distribution they operate on shifts away from the distribution they were trained on. A fraud detection model trained on 2022 transaction patterns will produce different results than 2025 transaction patterns, not because it was built incorrectly, but because the world it operates in has changed. Without continuous monitoring and a defined retraining trigger, that degradation is invisible until a business consequence makes it visible.
The organizational dimension is equally important. If the model was built by the data science team and handed to IT for infrastructure management, and the business unit considers its involvement complete at the sign-off meeting, then no one is monitoring the output for business accuracy. No one escalates when the model’s predictions are no longer aligning with what the business knows to be true. No one has the authority to trigger a retraining or to recommend decommissioning. The model runs. The business trusts it because no one has told them not to. And the damage accumulates silently.
According to Gartner, 70 percent of enterprises will operationalize AI architectures using MLOps frameworks, with sectors including financial services, healthcare, and retail adopting them to deploy AI-powered capabilities consistently and at scale. MLOps provides the structural answer to the ownership problem: automated monitoring, drift detection alerts, retraining pipelines, versioning, and audit trails that ensure the model remains fit for purpose after the initial deployment team has moved on to the next build.
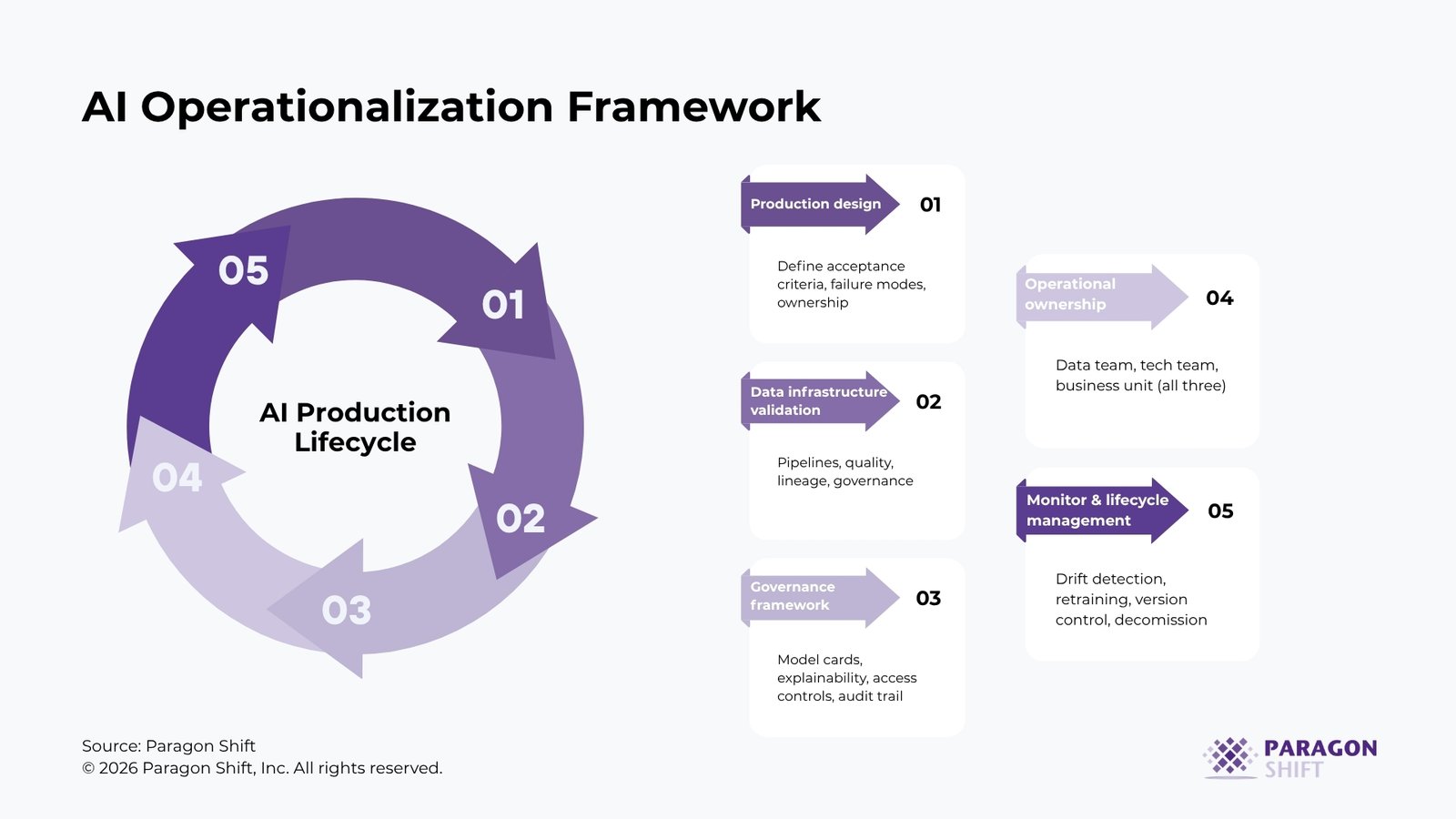
The AI Operationalization Framework
The four failure patterns above point to four structural requirements for reliably moving AI from POC to production. Together, they form the operationalization framework that CDOs and CDAOs need in place before a model is deployed at scale.
Stage 1: Production design during the POC
Before the proof of concept begins, define the production acceptance criteria. What performance threshold does the model need to sustain on live data before it is approved for deployment? What are the failure modes, and what happens operationally when the model encounters one? Who is the business owner of the model output, and what are they accountable for? The POC is designed to answer a narrow technical question. The production design answers the broader organizational one.
Stage 2: Data infrastructure validation
Before development moves beyond the POC, the data infrastructure for production must be assessed explicitly against the model’s requirements. This includes the reliability of the data pipelines feeding the model, the consistency of field definitions across source systems, the quality monitoring applied to training and inference data, and the lineage documentation required for governance. If the assessment surfaces gaps, they are addressed before productionization begins, not during it.
At Paragon Shift, this is the stage where our Data Modernization and AI & Automation practices work together most directly. The data foundation assessment is not a preliminary formality. It is often where we identify the conditions that would have caused a well-designed model to fail in production within six months.
Stage 3: Governance framework design
Before deployment, the governance documentation must be complete: model cards describing the training data, the intended use, and the known limitations; an explainability approach appropriate to the regulatory environment; access controls governing who can query the model and who can modify it; a monitoring specification defining what is tracked, at what frequency, and what triggers a review; and an escalation path for anomalous outputs. In regulated industries, this documentation is reviewed by compliance before deployment, not after.
Stage 4: Operational ownership assignment
Before go-live, the ownership structure for the model in production must be documented and agreed upon across three functions. The data team owns the pipeline quality and retraining triggers. The technology team owns the infrastructure, monitoring tooling, and integration reliability. The business unit owns the output: they review it, escalate when it behaves unexpectedly, and maintain the authority to request a model review or suspension when business context changes.
Stage 5: Continuous monitoring and lifecycle management
Production AI is a managed service, not a delivered product. Monitoring must track model performance against the baseline established during deployment, data quality through the inference pipeline, and output distribution against expected ranges. Retraining schedules must be defined proactively rather than triggered reactively. Version control must ensure that any change to the model or its training data is documented, tested, and deployed through a controlled process. And a decommissioning standard must exist so that models are retired on defined criteria and not simply abandoned when the business loses confidence in them.
At Paragon Shift, the engagements that produce models still running reliably in production two years after deployment are the ones that followed this sequence. The ones that stall or fail are almost always the ones that compressed stages two and three in the interest of moving faster, and then in production, what the shortcuts had cost them is discovered.
Key Takeaways
1. The gap between POC and production is structural, not technical. The failure patterns are consistent and predictable: inadequate POC design, unprepared data infrastructure, governance built after deployment rather than before, and absence of ownership after go-live.
2. Gartner found that only 48 percent of AI projects reach production, and those that do take an average of eight months to get there. The organizations that beat that timeline are the ones that address the structural requirements before building, not after.
3. Data readiness is the most frequently underestimated prerequisite. A model performing well on curated POC data will degrade in production if the data infrastructure feeding it is inconsistent or ungoverned.
4. Governance is not a post-deployment activity. Explainability, lineage documentation, access controls, monitoring specifications, and decommissioning criteria must be designed before a model goes live, particularly in regulated industries.
5. Production AI requires a three-party ownership model: the data team owns pipeline quality, the technology team owns infrastructure reliability, and the business unit owns the output and its business consequences.
6. MLOps has become the operational discipline that makes sustained production of AI viable. Building models is no longer the bottleneck. Governing and maintaining them at scale is.
Conclusion
The organizations that are generating sustained returns from AI in 2025 are not those that ran the most proofs of concept. They are the ones who built the conditions for production before they started building models. Data infrastructure that can support reliable inference. Governance frameworks that can withstand regulatory and audit scrutiny. Ownership structures that maintain accountability for model outputs long after the initial deployment team has moved on.
Those conditions are not glamorous. They do not appear in vendor demonstrations. They do not generate the kind of headlines that proof-of-concept announcements do. But they are what separates a POC that demonstrates potential from a production system that delivers on it.


